Session 09: Advanced App Porting
Reminders
At this stage, you should be familiar with the steps of configuring, building and running any application within Unikraft and know the main parts of the architecture. Below you can see a list of the commands you have used so far, and will be useful in today’s session as well.
| Command | Description |
|---|---|
make clean | Clean the application |
make properclean | Clean the application, fully remove the build/ folder |
make distclean | Clean the application, also remove .config |
make menuconfig | Configure application through the main menu |
make | Build configured application (in .config) |
qemu-guest -k <kernel_image> | Start the unikernel |
qemu-guest -k <kernel_image> -e <directory> | Start the unikernel with a filesystem mapping of fs0 id from <directory> |
qemu-guest -k <kernel_image> -g <port> -P | Start the unikernel in debug mode, with GDB server on port <port> |
Overview
As programs may grow quite complicated, porting them requires a thorough grasp of Unikraft core components, and in certain cases, the addition of new ones. In this session, we’ll take a closer look at Unikraft’s core libraries and APIs.
Adding New Sections to an ELF
There are situations in which we want to add new sections in the executable file (ELF format - Executable and Linking Format) for our application or library.
The reason these sections are useful is that the library (or application) becomes much easier to configure, thus serving more purposes.
For example, the Unikraft virtual filesystem (i.e. the vfscore library) uses such a section in which it registers the used filesystem (ramfs, 9pfs), and we are going to discuss this in the following sections.
Another component that makes use of additional sections is the scheduler.
The scheduler interface allows us to register a set of functions at build time that will be called when a thread is created or at the end of its execution.
The way we can add such a section in our application/library is the following:
Create a file with the
.ldextension (e.g. extra.ld) with the following content:SECTIONS { .my_section : { PROVIDE(my_section_start = .); KEEP (*(.my_section_entry)) PROVIDE(my_section_end = .); } } INSERT AFTER .text;Add the following line to
Makefile.uk:LIBYOURAPPNAME_SRCS-$(CONFIG_LIBYOURAPPNAME) += $(LIBYOURAPPNAME_BASE)/extra.ldThis will add the
.my_sectionsection after the.textsection in the ELF file. The.my_section_entryfield will be used to register an entry in this section, and access to it is generally gained via traversing the section’s endpoints (i.e. frommy_section_starttomy_section_end).
But enough with the chit-chat, let’s get our hands dirty.
In the /demo/01-extrald-app directory there is an application that defines a new section in the ELF.
Copy this directory to your app’s directory.
Your working directory should look like this:
workdir
|_______apps
| |_______01-extrald-app
|_______libs
|_______unikraft
Before running the program let’s analyze the source code.
Look in the main.c file.
We want to register the my-structure structure in the newly added section.
In Unikraft core libraries this is usually done using macros.
So we will do the same.
#define MY_REGISTER(s, f) static const struct my_structure \
__section(".my_section_entry") \
__my_section_var __used = \
{.name = (s), \
.func = (f)};
This macro receives the fields of the structure and defines a variable called __my_section_var in the newly added section.
This is done via __section().
We also use the __used attribute to tell the compiler not to optimize out the variable.
Note that this macro uses different compiler attributes.
Most of these are in uk/essentials.h, so please make sure you include it when working with macros.
Next, let’s analyze the method by which we can go through this section to find the entries. We must first import the endpoints of the section. It can be done as follows:
extern const struct my_structure my_section_start;
extern const struct my_structure my_section_end;
Using the endpoints we can write the macro for iterating through the section:
#define for_each_entry(iter) \
for (iter = &my_section_start; \
iter < &my_section_end; \
iter++)
Note
If you’re not familiar with macros, you may check what they expand to with the GCC’s preprocessor. Remove all the included headers and rungcc -E main.c.Let’s configure the program.
Use the make menuconfig command to set the KVM platform as in the following image.
Save the configuration, exit the menuconfig tab and run make.
Now, let’s run it.
You can use the following command:
$ qemu-guest -k build/01-extrald-app_kvm-x86_64
The program’s output should be the following:
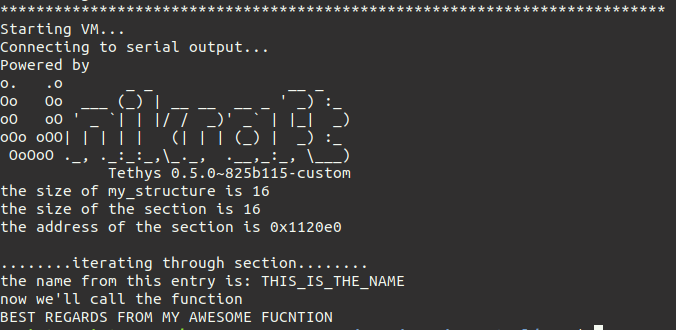
To see that the information about the section size and its start address is correct we will examine the binary using the readelf utility. The readelf utility is used to display information about ELF files, like sections or segments. More about it here Use the following command to display information about the ELF sections:
$ readelf -S build/01-extrald-app_kvm-x86_64
The output should look like this:
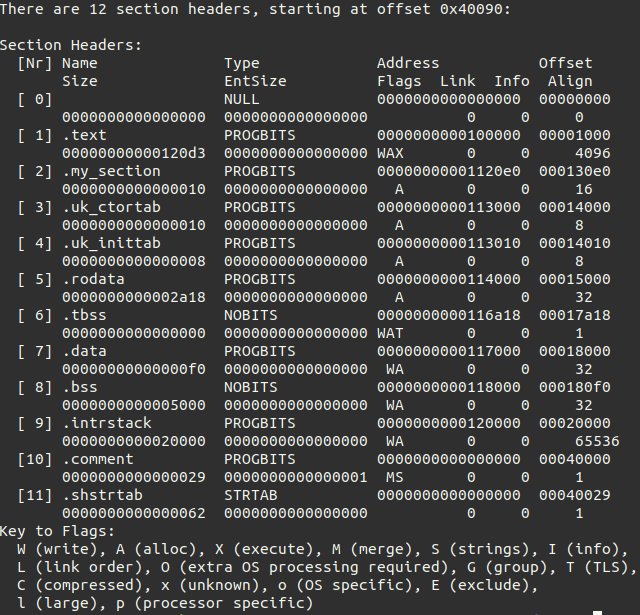
We can see that my_section is indeed among the sections of the ELF.
Looking at its size we see that it is 0x10 bytes (the equivalent of 16 in decimal).
We also notice that the start address of the section is 0x1120f0, the same as the one we got from running the program.
Unikraft APIs
One important thing to point out regarding Unikraft internal libraries is that for each “category” of library (e.g., memory allocators, schedulers, filesystems, network drivers, etc.) Unikraft defines (or will define) an API that each library under that category must comply with. This is so that it’s possible to easily plug and play different libraries of a certain type (e.g., using a co-operative scheduler or a pre-emptive one).
VFScore
Take for example the virtual filesystem (i.e. vfscore).
This library provides the implementation of system calls related to filesystem management.
We saw in previous sessions that there are two types of filesystems available in Unikraft ramfs and 9pfs.
Obviously, these two have different implementations of generic file operations, such as reading, writing, etc.
The natural question is: how can we have the same API for system calls (e.g. read, write) but with configurable functionalities?
The answer is by mapping system calls to different implementations.
This is done by using function pointers that redirect the program’s flow to the functions we have defined.
In this regard, the vfscore library provides 2 structures to define operations on the filesystem:
struct vfsops {
int (*vfs_mount) (struct mount *, const char *, int, const void *);
...
struct vnops *vfs_vnops;
};
struct vnops {
vnop_open_t vop_open;
vnop_close_t vop_close;
vnop_read_t vop_read;
vnop_write_t vop_write;
vnop_seek_t vop_seek;
vnop_ioctl_t vop_ioctl;
...
};
The first structure mainly defines the operation of mounting the filesystem, while the second defines the operations that can be executed on files (regular files, directories, etc).
The vnops structure can be seen as the file_operation structure in the Linux Kernel (more as an idea).
More about this structure here.
The filesystem library will define two such structures through which it will provide the specified operations. To understand how these operations end up being used let’s examine the open system call:
int
sys_open(char *path, int flags, mode_t mode, struct vfscore_file **fpp)
{
struct vfscore_file *fp;
struct vnode *vp;
...
error = VOP_OPEN(vp, fp);
}
VOP_OPEN() is a macro that is defined as follows:
#define VOP_OPEN(VP, FP) ((VP)->v_op->vop_open)(FP)
So the system call will eventually call the registered operation.
Note
In order to find the source that contains the definition of a structure, function or other component in the unikraft directory you can use the following command:
$ grep -r <what_you_want_to_search_for>
For example:

Let’s see now how to link the “file operations” of a filesystem to the vfscore library.
For this, the library exposes a specific structure named vfscore_fs_type:
struct vfscore_fs_type {
const char *vs_name; /* name of file system */
int (*vs_init)(void); /* initialize routine */
struct vfsops *vs_op; /* pointer to vfs operation */
};
Notice that this structure contains a pointer to the vfsops structure, which in turn contains the vnops structure.
To register a filesystem, the vfscore library uses an additional section in the ELF.
You can inspect the extra.ld file, in the vfscore directory to see it.
As we mentioned before, these sections come with help macros, so this time is no exception either.
The macro that registers a filesystem is:
UK_FS_REGISTER(fssw)
Where the fssw argument is a vfscore_fs_type structure.
There are three other important structures that we should discuss.
First of all, the vnode structure.
This is the abstraction that vfscore provides for a file (no matter its nature, regular, directory, etc), and it can be seen as the equivalent of an inode in Linux-based systems.
struct vnode {
uint64_t v_ino; /* inode number */
struct mount *v_mount; /* mounted vfs pointer */
struct vnops *v_op; /* vnode operations */
mode_t v_mode; /* file mode */
off_t v_size; /* file size */
...
void *v_data; /* private data for fs */
};
This structure maintains the metadata of the file, such as the operations we can perform on it, permissions, or the size of the file. In addition to this, we notice the existence of a void pointer field which is used to keep a reference to the specific structures of the filesystem. This field is used by the two available filesystems and we will use it today in our practical work.
The dentry structure is the second relevant structure. It offers the possibility to create links (although currently neither ramfs or 9pfs does not support hard links).
A dentry can be seen as the equivalent of a path in the filesystem, and it has a pointer to the inode.
struct dentry {
char *d_path; /* pointer to path in fs */
struct vnode *d_vnode; /* pointer to inode */
...
};
One thing to point out is that an inode is deleted only when there are no dentries that reference it.
Last but not least is the mount structure.
Mounting filesystems is the process by which the user makes the contents of a filesystem accessible.
From this point of view, the filesystem, for example, ramfs, is seen as a device on Linux to which we have to associate a directory (technically speaking a dentry).
struct mount {
struct vfsops *m_op; /* pointer to vfs operation */
int m_flags; /* mount flag */
char m_path[PATH_MAX]; /* mounted path */
...
struct dentry *m_root; /* root vnode */
};
Notice that the mount structure does have a dentry which will point to the inode describing the root directory.
RAMFS
Now that we have seen the API of the virtual filesystem, let’s go deeper into the hierarchy and look at the implementation of the ramfs filesystem. For storage, this uses, as the name implies, the memory. Its advantage is that it is very fast, the disadvantage you probably already guessed it… From a simplified perspective we can look at a file in ramfs as a buffer in memory. But wait a minute, if a file is just a memory buffer, doesn’t going through so many layers of code mean overhead? Bien sûr, mi amigo! But having these methods of abstraction makes our work easier in terms of porting an application. There are applications that need a small filesystem, although the source code is not very easy. Then we prefer a little overhead than trying to patch the code.
Let’s see how the ramfs system is registered into vfscore. We inspect the code from the ramfs_vfsops.c file from ramfs directory:
static struct vfscore_fs_type fs_ramfs = {
.vs_name = "ramfs",
.vs_init = NULL,
.vs_op = &ramfs_vfsops,
};
UK_FS_REGISTER(fs_ramfs);
It defines the vfscore_fs_type structure and uses the registration macro for the corresponding section.
Next, let’s look at the specific structure, which is essentially the “file”:
struct ramfs_node {
struct ramfs_node *rn_next; /* next node in the same directory */
struct ramfs_node *rn_child; /* first child node */
int rn_type; /* file or directory */
char *rn_name; /* name (null-terminated) */
char *rn_buf; /* buffer to the file data */
size_t rn_bufsize; /* allocated buffer size */
...
};
This structure contains the file type, the buffer in which the data will be stored, and its size. A field that normally should not be here is the name, but for the simplicity of the library, it is used. Unfortunately, the fact that the name field is here and is used in the code does not allow the creation of hard links.
We notice that the filesystem has the following tree-like structure:
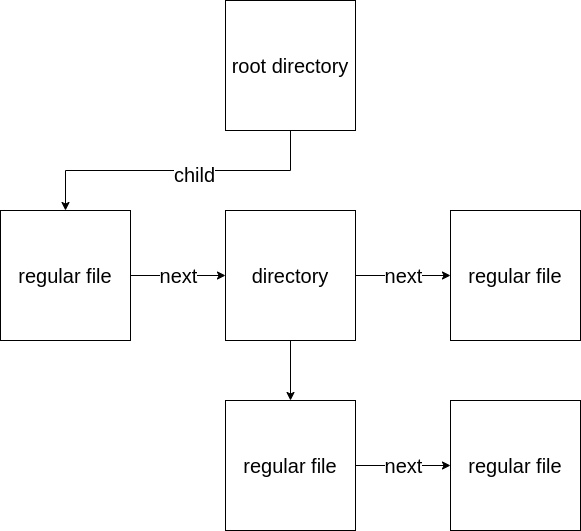
Let’s look at how the filesystem is mounted.
In the boot process, the mount syscall from vfscore is called.
This is redirected to the ramfs_mount function as follows:
UK_SYSCALL_R_DEFINE(int, mount, const char*, dev, const char*, dir,
const char*, fsname, unsigned long, flags, const void*, data)
{
...
/*
* Call a file system specific routine.
*/
if ((error = VFS_MOUNT(mp, dev, flags, data)) != 0)
goto err4;
...
}
Now let’s examine this specific routine:
/*
* Mount a file system.
*/
static int
ramfs_mount(struct mount *mp, const char *dev __unused,
int flags __unused, const void *data __unused)
{
struct ramfs_node *np;
/* Create a root node */
np = ramfs_allocate_node("/", VDIR);
mp->m_root->d_vnode->v_data = np;
return 0;
}
If we go back to the 3 important structures of vfscore, mount, dentry and vnode we notice this call provides the upper layer the possibility to explore all the file hierarchy.
The reason why it is important to do the vnode - ramfs_node association is that most operations are done on vnodes.
Thus, in the first phases of a defined operation, references to the ramfs_node field are usually found.
For example:
static int
ramfs_read(struct vnode *vp, struct vfscore_file *fp __unused,
struct uio *uio, int ioflag __unused)
{
struct ramfs_node *np = vp->v_data;
...
}
Generic List API in Unikraft
Unikraft has an implementation of generic lists similar to those in the Linux kernel.
To use this API, one must include the uk/list.h header.
This type of structure is important because it is a unified way of using linked lists, which is why it is useful to know it, especially if we are working in the Unikraft core.
The uk_list_head structure looks as follows:
struct uk_list_head {
struct uk_list_head *next;
struct uk_list_head *prev;
};
The way these lists are built exploits the way of defining structures in C.
A field in a structure is actually just an offset in memory.
To define a list, for example, we just need to include the uk_list_head structure in our container structure:
struct car {
char name[50];
struct uk_list_head list;
};
All the list operations, adding, removing, traversing will be performed on the list field.
The usual routines from this API are:
UK_LIST_HEAD(name)declare the sentinel of a list globally.UK_INIT_LIST_HEAD(struct uk_list_head *list)declare the sentinel of a list dynamically (i.e. can be used inside a function).uk_list_add(struct uk_list_head *new_entry, struct uk_list_head *head)add a new entry to the list.uk_list_entry(ptr, type, field)returns the structure with the type type that contains the element ptr from the list, having the name field within the structure.uk_list_for_each(p, head)iterates over a list using p as a cursor.uk_list_for_each_safe(p, n, head)iterates over a list using p as a cursor and n as a temporary cursor. This is useful for deletion.
In the /demo/02-linked-list-app directory there is an application that uses generic lists.
Copy this directory to your app’s directory.
Run make menuconfig and select the KVM platform.
After that run make.
You can start the program using the following command:
$ qemu-guest -k build/02-linked-list-app_kvm-x86_64
Let’s look at the following part of the code:
printf("\nThe structure address for c1 is: %p\n", c1);
zero = (struct car *) 0;
printf("The offset of list field inside car strucure is: %p\n",
&zero->list);
printf("The list field address for c1 is: %p\n",
&c1->list);
printf("The address of c1 based on calculation is %p\n",
(void *) ((void *) &c1->list - (void *) &zero->list));
In this part we calculate the offset of the list field within the car structure, which we subtract from the actual address of the list field inside the structure to determine the start address.
This is precisely the way uk_list_entry macro works.
Practical Work
All tasks are in the work directory.
Support Files
Session support files are available in the repository. If you already cloned the repository, update it and enter the session directory:
$ cd path/to/repository/clone
$ git pull --rebase
$ cd content/en/docs/sessions/09-advanced-app-porting/
$ ls
demo/ images/ index.md/ sol/ work/
If you haven’t cloned the repository yet, clone it and enter the session directory:
$ git clone https://github.com/unikraft/summer-of-code-2021
$ cd summer-of-code-2021/content/en/docs/sessions/09-advanced-app-porting/
$ ls
demo/ images/ index.md/ sol/ work/
01. Add Extra Section in the ELF
In this task we will add a new section in the elf and we will define a series of macros.
Navigate to the 01-extrald directory.
Copy mycorelibrary to the lib directory in unikraft and the two applications in the apps directory.
Your working directory should look like this:
workdir
|_______apps
| |_______01-app
| |_______02-app
|_______libs
|_______unikraft
|_______lib
|_______mycorelib
|_______Makefile.uk
Edit the Makefile.uk from the lib directory and add the following:
$(eval $(call _import_lib,$(CONFIG_UK_BASE)/lib/mycorelib))
Follow the TODOs from the sources and headers.
After solving all the TODOs compile both applications and run them.
Don’t forget to make menuconfig to select mycorelib and the KVM platform.
02. Using readelf
Use the readelf utility to see the section’s address and size and check them with the program’s output (like we did in the demo).
03. Searching Symbols
Using the grep utility search the following and inspect the source code:
struct vfsops,struct vnops,struct vfscore_fs_typestruct vnode,struct dentry,struct mountsys_openlook especially for VOP macros. How many operations does the open system call do?vfscore_vgetcan you figure it out what this function does?
04. MyRamfs. Register the Filesystem.
In the following exercises, we will build step by step a simplified version of the ramfs library.
The first step is to register the filesystem into vfscore.
Navigate to the 04-05-06-myramfs directory.
Copy myramfs directory to the lib directory in unikraft and the application in the apps directory.
Your working directory should look like this:
workdir
|_______apps
| |_______ramfs-app
|_______libs
|_______unikraft
|_______lib
|_______myramfs
|_______vfscore
|_______Makefile.uk
Edit the Makefile.uk from the lib directory and add the following:
$(eval $(call _import_lib,$(CONFIG_UK_BASE)/lib/myramfs))
Now we need to make our library configurable from vfscore, for this we will need to edit the Config.uk file in the vfscore directory.
First we will add the configuration menu:
...
if LIBVFSCORE_AUTOMOUNT_ROOTFS
choice LIBVFSCORE_ROOTFS
prompt "Default root filesystem"
config LIBVFSCORE_ROOTFS_RAMFS
bool "RamFS"
select LIBRAMFS
config LIBVFSCORE_ROOTFS_MYRAMFS
bool "My-ramfs"
select LIBMYRAMFS
...If we run now make menuconfig in the application ramfs-app we should see our library under the vfscore configuration:
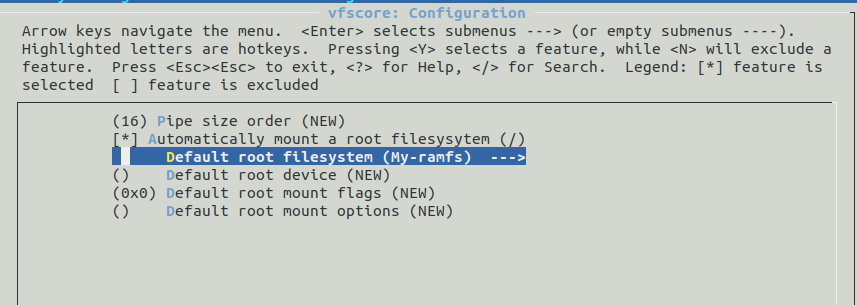
The second fundamental step is to add the following line to the same Config.uk file:
# Hidden configuration option that gets automatically filled
# with the selected filesystem name
config LIBVFSCORE_ROOTFS
string
default "ramfs" if LIBVFSCORE_ROOTFS_RAMFS
default "myramfs" if LIBVFSCORE_ROOTFS_MYRAMFS
default "9pfs" if LIBVFSCORE_ROOTFS_9PFS
default "initrd" if LIBVFSCORE_ROOTFS_INITRD
default LIBVFSCORE_ROOTFS_CUSTOM_ARG if LIBVFSCORE_ROOTFS_CUSTOMThis will fill the CONFIG_LIBVFSCORE_ROOTFS with the string myramfs.
Now that we’ve done our setup, let’s get started.
Follow TODOs 1-4 in myramfs_vnops.c and myramfs_vfsops.c.
Now, when you run make menuconfig in the app be sure you use the myramfslibrary and also check the debug library.
If everything is fine you should get a similar output:
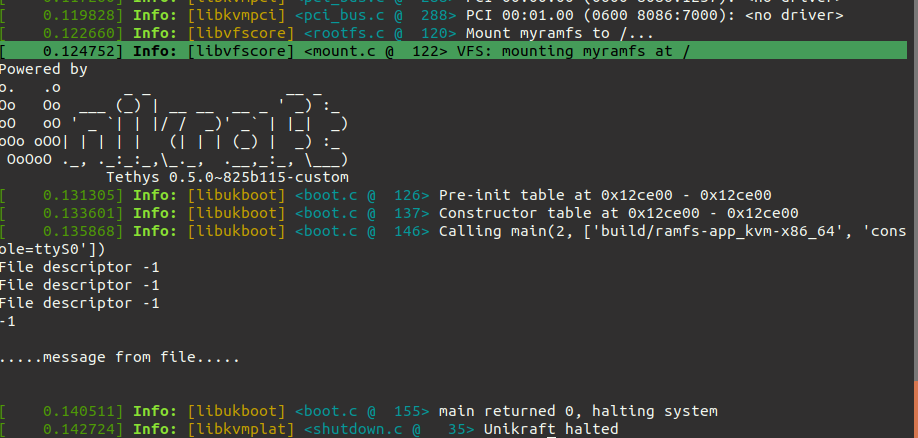
Note
Try to rename the filesystem in thevfscore_fs_type structure. What happens? Look for the fs_getfs function.05. MyRamfs. Building the Structure
The ramfs library has a tree-like structure, as we saw in the section dedicated to it.
Our library will be in the form of a list for ease of use.
We’ll use the generic lists given before to make it even prettier.
This indicates that only ordinary files, not directories, are supported.
For this task we will still look in the files myramfs_vfsops.c and myramfs_vnops.c and we will perform the TODOs from 5 to 13.
But first we recommend you to look at the struct myramfs_node which is in the myramfs.h file.
To test this task go back to the ramfs-app and build it again (make sure to properclean).
If you solved everything correctly the output should look like this:
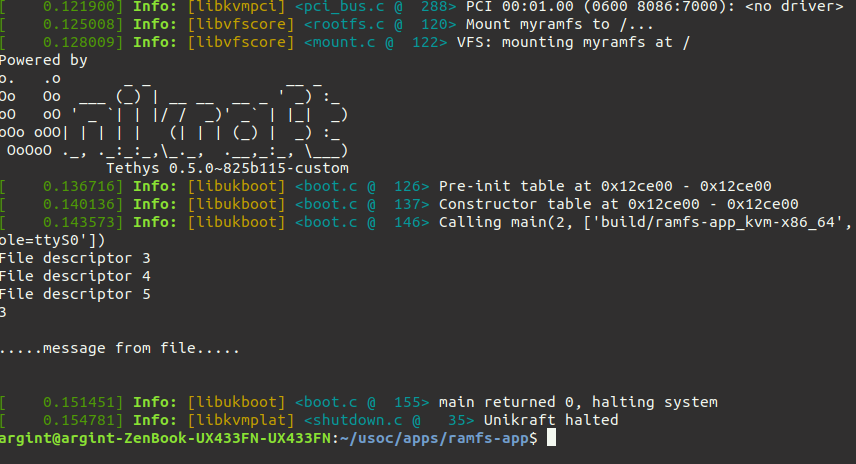
06. MyRamfs. Reading and Writing
In today’s last exercise we will really do what is done most with files, we write and read. Follow TODOs 14, 15 from myramfs_vnops.c.
HINT
Checkstruct uio structure and the vfscore_uiomove routine.07. Give Us Feedback
We want to know how to make the next sessions better. For this we need your feedback.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.